Vol. 11 No. 3, April 2006
| Vol. 11 No. 3, April 2006 | ||||
Introducción. Con el advenimiento de la web a principios de los años 90, el volumen de información electrónica ha experimentado un crecimiento exponencial sin precedentes. Este fenómeno introdujo muchas ventajas en relación con la posibilidad de intercambio, difusión y transferencia de datos pero, sin embargo, acarreó igualmente muchos problemas en relación con el acceso, búsqueda, localización y recuperación de la información relevante dentro de grandes volúmenes de datos.
Objetivo. El presente trabajo realiza una revisión exhaustiva de los diferentes modelos, métodos y algoritmos existentes para la generación de Interfaces Visuales de Recuperación de Información (VIRIs, Visual Interfaces for Information Retrieval), clasificados según la etapa del proceso en la que intervienen: análisis y transformación de los datos, aplicación de los algoritmos de clasificación y distribución visual, y aplicación de técnicas de transformación visual.
Metodología. En base a su análisis, se comparan los diferentes métodos a emplear en cada etapa del proceso de producción, así como se determinan qué combinaciones entre métodos y algoritmos de diferentes etapas resultan más adecuadas.
Resultados. En la primer sección, análisis y transformación de datos, se analiza la minería de contenidos, de estructura y de uso. En la segunda sección, algoritmos de clasificación y distribución visual, se muestran las representaciones jerárquicas, de redes, de dispersión y mapas. Finalmente, entre las técnicas de transformación visual se presentan las técnicas no orientadas a la distorsión visual y las orientadas a la distorsión (Focus+Context).
Conclusiones. Los resultados pretenden servir a otros investigadores como herramienta para la elección de una u otra combinación metodológica en el desarrollo de propuestas específicas de VIRIs, además de sugerir implicaciones a tener en cuenta en la necesaria investigación sobre nuevas técnicas de transformación visual.
Con el advenimiento de la World Wide Web a principios de los años 90, el volumen de información electrónica ha experimentado un crecimiento exponencial sin precedentes. Este fenómeno introdujo muchas ventajas en relación con la posibilidad de intercambio, difusión y transferencia de datos pero, sin embargo, acarreó igualmente muchos problemas en relación con el acceso, búsqueda, localización y recuperación de la información relevante dentro de grandes volúmenes de datos.
La investigación en técnicas de recuperación de información ha abordado esta problemática dividiéndola para su estudio en dos grandes estrategias: el querying (interrogación) y el browsing (exploración).
En las estrategias de búsqueda basadas en querying , el usuario introduce una serie de palabras clave que expresen sus necesidades de información, con lo que el sistema tras realizar una equiparación entre consulta y espacio documental, devolverá al usuario una lista de resultados pertinentes para la consulta introducida. Se trata por tanto de una estrategia de búsqueda consciente, que requiere del usuario una formalización previa de sus necesidades de información.
Es los sistemas basados en querying , se debe distinguir entre sistemas de recuperación de datos y recuperación de información (Rijsbergen 1975). Esta diferenciación está motivada principalmente por la técnica que emplean para la equiparación entre consulta y espacio documental, denominadas equiparación exacta y equiparación parcial respectivamente.
La equiparación exacta es un método determinista de comparación entre consulta y conjunto documental, en el que únicamente se resuelven como resultados válidos aquellos documentos que cumplen completamente con las necesidades expresadas en la consulta. En otras palabras, sólo se devolverían como resultados aquellos documentos donde aparecieran todos y cada uno de los términos introducidos en la consulta, aparición que es contabilizada de forma binaria (presencia o ausencia).
En cambio, la equiparación parcial es un método que posibilita tanto la obtención de resultados parcialmente válidos o pertinentes, como la ordenación de estos resultados en función de su grado de relevancia para la consulta introducida. Para ello, el sistema debería hacer uso de algún modelo que proporcione:
Entre los diferentes modelos propuestos que cumplen con estos requisitos podemos señalar: Modelo del espacio vectorial, Modelo probabilístico y Modelo de conjuntos difusos.
De estos modelos, el Modelo del espacio vectorial, originalmente propuesto por Salton (1989), es el que ha tenido un mayor éxito. Como indica Moya-Anegón (1994), el probabilístico tiene unos fundamentos muy similares pero una implementación más compleja, y el de conjuntos difusos aún se encuentra poco desarrollado.
En el Modelo de espacio vectorial, la representación de los datos se obtiene mediante la vectorización del conjunto documental: cada documento d se representa por un vector V de términos t, generando una matriz � o espacio - multidimensional con tantas columnas como términos, y filas como documentos.
Partiendo de la premisa de que los términos de un documento representan su contenido (Luhn 1958), la ponderación de cada uno de sus términos se realiza a través de la función tf · idf, donde la frecuencia del término (tf = term frequency) determina la capacidad de representación de un término para un documento dado, y la inversa de la frecuencia del término en todo el conjunto documental (idf = inverse document frequency) determina su capacidad de discriminación.
Como vemos, este método de ponderación permite detectar los términos más significativos para cada documento, un paso necesario para realizar la indización automática del contenido del documento.
Una vez representado numéricamente el conjunto documental y ponderado de forma automática cada uno de los términos de cada documento, la equiparación parcial se obtiene comparando, mediante el uso de funciones de similaridad, la representación vectorizada de la consulta con las de los documentos.
Las funciones de similaridad, como indica Moya-Anegón (1994), son aportaciones que en el campo de la matemática aplicada se habían hecho anteriormente, y que han sido aplicadas al campo de la recuperación de información. Funciones de similaridad hay muchas, pero las que mejores resultados ofrecen son las que se basan en el producto escalar: la del coseno (también llamada de Salton), la de Dice y la de Jaccard.
Estas funciones, aplicadas sobre dos vectores, devuelven como resultado un valor que indica en qué grado se parecen dichos vectores. Por tanto, al ser aplicadas sobre el vector de la consulta y el de cada uno de los documentos, podemos obtener una medida del grado de relevancia que para esa consulta tienen cada uno de los documentos en un repositorio documental determinado.
Como vemos, la mayor ventaja que implica el empleo de técnicas de equiparación parcial, y por tanto el modelo de espacio vectorial, es que posibilitan la ordenación de los resultados en función del grado de certidumbre de que sean relevantes para las necesidades del usuario. Por el contrario, la equiparación exacta únicamente puede determinar si un resultado es válido para una consulta dada, pero no en qué grado, imposibilitando la ordenación de resultados por relevancia. Como sucedáneo la ordenación podría hacerse, no obstante, en base a atributos menos útiles como podría ser la fecha de creación, nombre del autor, etc.
Aunque el querying es la estrategia de acceso a la información actualmente más extendida en la Web y más estudiada en la literatura científica, no siempre resulta suficiente para satisfacer las necesidades del usuario. Cuando el usuario no tiene completamente claro qué está buscando o cuando es incapaz o tiene dificultades para formalizar sus necesidades de información a través del lenguaje de consulta, se requiere de un modelo alternativo o complementario que posibilite al usuario otra vía de acceso a la información.
En la estrategia de búsqueda por bowsing , en oposición al querying , el usuario explora o inspecciona el conjunto documental, sin necesidad de tener que expresar de forma previa cuáles son sus necesidades de información. Esta es una estrategia que usamos en numerosas situaciones de nuestra vida cotidiana (como cuando exploramos las estanterías de una biblioteca o librería en busca de un libro), pero si nos circunscribimos al medio digital, el mejor ejemplo de búsqueda por browsing es la actividad de navegación hipertextual, donde el usuario explora visual y 'espacialmente' el conjunto hiperdocumental con el objetivo de encontrar o localizar información de su interés.
Entre los sistemas de recuperación de información que ofrecen la posibilidad de búsqueda por browsing , cabe destacar aquellos que proveen de un medio específico para realizar browsing gráfico, en forma de representaciones visuales e interactivas resultado de la abstracción gráfica del conjunto documental.
En la tipología de estas representaciones gráficas o visuales, una primera diferenciación que podemos realizar tiene como base el método utilizado para generarlas, distinguiendo así entre representaciones basadas en técnicas artesanales o manuales, y las basadas en técnicas automáticas. Las primeras presentan varios problemas, ya que no reflejan la estructura real de los datos a representar sino una visión subjetiva que de éstos tiene una determinada persona o grupo de personas. Además, presentan problemas relacionados con su escalabilidad y coste de realización. Por estas razones, en este trabajo solo se tendrán en cuenta aquellas generadas de forma automática.
Una de las áreas de investigación más prometedoras basadas en este modelo de browsing gráfico es aquella representada por los estudios en Visualización de Información o Visualización Científica, distinción terminológica condicionada a la naturaleza de los datos a representar (Polanco & Zartl 2002), más concretamente los estudios enfocados al diseño de Interfaces Visuales para la recuperación de información o VIRIs (Visual Interfaces for Information Retrieval).
El concepto de visualización, según el diccionario de la Real Academia de la Lengua, hace referencia a la acción y efecto tanto de formar en la mente una imagen visual de un concepto abstracto, como de representar mediante imágenes ópticas fenómenos de otro carácter. Aplicado al contexto de la Visualización de Información (VI), el término describiría tanto el hecho de generar una representación visual de un conjunto complejo de datos, como el fenómeno de percepción y comprensión de dicha representación por el usuario final. En palabras de Dürsteler (2002), la VI es un proceso de interiorización del conocimiento mediante la percepción de información, construcción mental que va más allá de la simple percepción sensorial.
Una definición de VI aplicada al diseño de 'Visual Interfaces for Information Retrieval' nos la ofrece Eick (2001), al afirmar que la es 'el área de investigación enfocada a la creación de interfaces visualmente ricas para ayudar al usuario a comprender y navegar a través de espacios de información complejos'.
En base a esta definición podemos distinguir claramente dos funciones de cualquier VIRI:
Aunque el browsing como estrategia de acceso a la información presenta algunos inconvenientes, entre otros la posibilidad de ocasionar en el usuario distracción respecto a su objetivo inicial (Marchionini 1995), como indica Herrero-Solana (2000) los sistemas basados en browsing no parecen ser sustituibles por otro tipo de técnicas basadas en el querying .
Esto es debido a que, al mismo tiempo, presentan ventajas para la recuperación de información exclusivas en estas interfaces (Lin 1997):
Además de estas ventajas, como sugiere Marcos-Mora (2004), el browsing resulta cómodo de usar porque es natural y similar a la forma de buscar objetos en el mundo físico, y porque también propicia el hallazgo de información de interés de manera fortuita.
En el trabajo de Börner, et al. (2003), los autores realizan una revisión exhaustiva de las diferentes etapas, técnicas y algoritmos para la producción de 'Visual Interfaces for Information Retrieval', sentando unas bases teóricas y metodológicas de amplia aceptación por parte de la comunidad científica dedicada a la VI. Igualmente, tanto Herrero-Solana (2000) como Marcos-Mora (2004) han llevado a cabo revisiones metodológicas similares, realizando un recorrido analítico de los diferentes 'Visual Interfaces for Information Retrieval' propuestos en la literatura científica, así como de las metodologías empleadas para su desarrollo.
El objetivo propuesto en el presente trabajo consiste en indagar en los métodos, técnicas y algoritmos recogidos en la literatura científica para la producción y desarrollo de 'Visual Interfaces for Information Retrieval'. Se pretende, en base a su análisis, comparar las diferentes técnicas a emplear en cada etapa del proceso de producción, así como las combinaciones más adecuadas entre técnicas de diferentes etapas. A diferencia de otros trabajos similares, se indagará más exhaustivamente en las técnicas de transformación y distorsión visual, que hasta la fecha no han recibido la atención que se merecen en la literatura sobre producción de 'Visual Interfaces for Information Retrieval'.
Este trabajo se ha estructurado en tres secciones correspondientes a las tres etapas o fases principales que conforman la mayoría de esquemas metodológicos propuestos para la producción automatizada de 'Visual Interfaces for Information Retrieval' (Chung, et al. 2003; Polanco & Zartl 2002; Turetken & Sharda 2003 y Börner et al. 2003):
El primer paso para visualizar espacios complejos de información es la indización automática del conjunto de documentos electrónicos, que al igual que en sistemas basados en querying normalmente se realiza en base al modelo de espacio vectorial originalmente propuesto por Salton (1989) .
Si por un lado el objetivo de este modelo de representación de datos en sistemas basados en querying consiste en posibilitar la equiparación parcial entre consulta y conjunto documental; en los sistemas basados en browsing gráfico el objetivo es posibilitar tanto la clasificación automática del conjunto documental como el descubrimiento de relaciones estructurales subyacentes.
Cuando los documentos electrónicos a indizar contienen información complementaria, como hiperenlaces o etiquetas de marcado que estructuren su contenido, ésta también puede ser vectorizada para su posterior aprovechamiento.
Una vez vectorizado el conjunto documental, sobre este espacio vectorial se pueden llevar a cabo una serie de análisis con el objetivo de descubrir relaciones semánticas entre documentos, así como entre términos. Se obtiene de esta forma una matriz de distancias N x N, siendo N el número de documentos o de términos.
Estas técnicas pueden ser englobadas bajo la categoría de Minería de Datos, que es definido como un proceso de descubrimiento de conocimiento (a priori desconocido) sobre repositorios de datos complejos, mediante la extracción de información 'oculta' y potencialmente útil en forma de patrones globales y relaciones estructurales implícitas entre datos (Kopanakis & Theodoulidis 2003).
Dentro de las técnicas de Minería de Datos encontramos tres tipos distintos: minería de contenido, minería de estructura y minería de uso (Berendt et al. 2002; Baeza-Yates 2004).
Si partimos de la premisa de que los términos de un documento representan su contenido, la co-ocurrencia de un mismo término en dos documentos diferentes establecería una relación semántica entre éstos. Si asumimos este hecho es posible calcular la similaridad entre dos documentos comparando los vectores de cada documento mediante � cómo comentábamos en la introducción - funciones de similaridad. Igualmente es posible calcular la similaridad entre términos, teniendo en cuenta que la aparición de dos términos en un mismo documento implicaría una relación semántica entre éstos.
Para asegurar la fiabilidad y consistencia de la indización automática de textos en lenguaje natural y reducir el número de términos diferentes, antes de contabilizar frecuencias de co-ocurrencia, en muchas ocasiones es prerrequisito llevar a cabo un control terminológico. Entre las técnicas a aplicar podemos señalar:
La minería de estructura no se refiere a la estructura propia de cada documento de forma aislada, sino a la estructura del espacio documental definida por los hiperenlaces entre sus documentos.
Cuando un documento hipervincula a otro documento, este enlace expresa una relación estructural explícita entre los dos documentos. Pero a través del análisis de estos hiperenlaces, también es posible descubrir estructuras implícitas y subyacentes de relación semántica entre documentos.
Este es el caso del análisis de la co-sitación, término que se refiere a la co-citación aplicada a los hiperenlaces o 'sitas' entre web sites. En este análisis que desde un mismo documento se enlace una pareja de documentos conjuntamente establece una relación semántica entre los documentos co-sitados.
Igualmente, se podría aplicar el análisis de los enlaces comunes (que en Bibliometría se suele denominar bibliographic coupling) para descubrir estructuras de similaridad subyacentes, en el que el hecho de que dos documentos enlacen a un mismo tercer documento establece una relación semántica implícita entre los documentos sitantes.
Cuando el espacio documental se encuentra accesible al público y visitado diariamente, la información recogida por el servidor en forma de ficheros de sesión (log files) puede aportarnos información adicional acerca de las relaciones semánticas entre el conjunto de documentos.
Por ejemplo, que un mismo usuario co-visite o co-acceda a dos documentos diferentes, establece una relación semántica entre los documentos, mayor cuanto mayor sea la frecuencia de este patrón de uso. Así mismo se podrían llevar a cabo análisis más complejos, teniendo en cuenta en qué orden secuencial son visitados los documentos.
Este análisis nos puede ofrecer información imposible de descubrir a través de la minería de contenido y de estructura, ya que dos documentos frecuentemente co-visitados puede que no se enlacen entre ellos, que no co-siten ni sean co-sitados, e incluso que no presenten co-ocurrencias de términos con una frecuencia relevante.
Los diferentes tipos de análisis indicados nos ofrecen una herramienta para revelar las relaciones semánticas de similaridad entre documentos, incluso entre términos, en base a nuestro espacio documental vectorizado. La información que ofrecen es complementaria, ya que como indicábamos, con un tipo de análisis es posible revelar información semántica que no hubiera podido ser descubierta mediante la única utilización del resto.
Por ello, aunque estos análisis pueden ser utilizados independientemente, su utilización conjunta aumentaría su capacidad para revelar información 'oculta'. En este sentido, Chen (1997, 1998) propone un modelo genérico para estructurar y visualizar espacios de información hipertextuales, denominado GSA (Generalised Similarity Análisis). Este modelo ofrece un esquema metodológico para la extracción de las relaciones semánticas entre documentos en base a tres tipos de medidas de similaridad - enlaces hipertextuales, similaridad de contenido y patrones de uso � unificadas bajo una única función, que el autor denomina de meta-similaridad.
En su tesis doctoral, Herrero-Solana (2000) propone una clasificación de los diferentes 'Visual Interfaces for Information Retrieval' en función de la estructura explícita de los datos a representar: jerárquicas, en red, de búsqueda, en líneas de tiempo y multidimensionales.
Cuando el 'Visual Interface for Information Retrieval'destinado a generar utilizará una metáfora visual fiel reflejo de la propia estructura de los datos, no resulta necesaria la aplicación de técnicas de clasificación y distribución visual, ni por tanto el paso metodológico que describimos a continuación.
Únicamente en 'Visual Interfaces for Information Retrieval' basados en estructuras de datos multidimensionales será imprescindible el empleo de éstas técnicas, que de forma automática produzcan una abstracción gráfica resultado de la reducción de este espacio n -dimensional a un número de dimensiones comprensibles y perceptibles por el ojo humano (1D, 2D ó 3D).
En este trabajo la clasificación de los diferentes tipos de técnicas y algoritmos se hará en función de la metáfora visual perseguida, y no de la propia estructura de los datos, ya que se entiende que siempre serán estructuras multidimensionales que necesitan ser reducidas o simplificadas.
Siguiendo el esquema propuesto por Lin (1997), podemos diferenciar entre los siguientes tipos de metáforas visuales: jerárquicas, de redes, de dispersión y mapas.
Este tipo de representación visual - donde los elementos se presentan en diferentes niveles, ramas o agrupaciones, que descienden de un nodo raíz - es la más común cuando la propia naturaleza del conjunto de datos a visualizar es jerárquica, como por ejemplo en la visualización de estructuras complejas de directorios y ficheros de sistemas informáticos.
En el caso de la visualización de estructuras de datos multidimensionales, donde no están definidas de forma explícita las relaciones jerárquicas entre estos, este tipo de visualización es consecuencia de la aplicación de técnicas de clasificación o agrupación.
Este es el caso de las técnicas estadísticas de clustering o análisis de conglomerados, que a través de un proceso iterativo van agrupando los diferentes elementos en función de su similaridad, así como agrupando los diferentes grupos en ramas o niveles jerárquicos.
Entre las técnicas de clustering podemos diferenciar alrededor de 150 tipos diferentes en base a las reglas de aglomeración utilizadas. Dentro de las reglas de aglomeración más comunes encontramos: encadenamiento simple (single link), también denominado método del vecino más cercano; encadenamiento completo (complete link), o método del vecino más lejano; encadenamiento promedio; y el método de Ward o método de la suma de cuadrados (Herrero-Solana 2000).
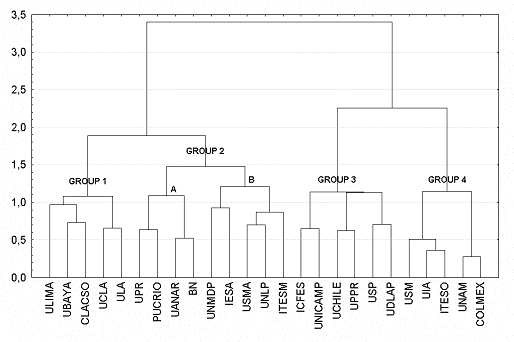
El resultado gráfico de la aplicación de estas técnicas suele ser en forma de dendograma como el de la figura 4 (representación que usa la metáfora visual de árbol jerárquico), donde se pueden apreciar visualmente los diferentes grupos y subgrupos generados. Para su uso en la producción de 'Visual Interfaces for Information Retrieval' se podrían representar mediante metáforas jerárquicas alternativas como las jerarquías hiperbólicas (Lamping, et al. 1995), o como los treemaps � representación plana de una jerarquía en un espacio bi-dimensional - (Shneiderman 1992; Kobourov & Yusufov 2005). Hay que señalar que los treemaps pueden ser considerados una metáfora visual híbrida entre representación jerárquica y mapa.
El mayor problema que presentan las técnicas de clustering es que no posibilitan el etiquetado o rotulado automático de cada uno de los grupos y subgrupos creados, por lo que el usuario sólo podría identificar la clase o grupo a través de la exploración de sus elementos contenidos.
Las representaciones de redes son aquellas donde los diferentes elementos � documentos, términos... � son presentados en forma de nodos o vértices, mientras que la estructura semántica se encuentra definida por los enlaces o arcos que conectan dichos nodos.
Por ejemplo, en base a una matriz de similaridad N x N (donde N indica el número de documentos), se podría representar cada documento como un nodo, y cada grado de similaridad entre dos documentos como un enlace o arco. El problema de representar estructuras de datos multidimensionales de esta forma es que el número de arcos sería tal que impediría la comprensión del grafo resultante, ya que el número de enlaces salientes por cada nodo podría llegar a ser igual a N-1.
Por tanto, es necesario el empleo de alguna técnica de 'poda' o reducción de enlaces con el fin de que el grafo resultante sea comprensible y por tanto útil para la visualización, sin perder ni distorsionar en la medida de lo posible la realidad estructural de la red.
Una de estas técnicas de 'poda' es el método de escalamiento de red Pathfinder (Schvaneveldt 1990), con el que se obtiene como resultado lo que se denominan redes Pathfinder o PFNETs. Esta técnica se basa en la eliminación de todos aquellos arcos de la red que no cumplan el criterio conocido como la 'condición de la inigualdad del triángulo', es decir, que no formen parte del camino más corto entre cada par de nodos.
La topología de la red resultante de la aplicación del método de Pathfinder estará condicionada por dos parámetros. Por un lado la métrica r de Minkowski, que determina cómo calcular la distancia entre dos nodos no enlazados directamente, parámetro que puede tomar tres valores: cuando r=0 la distancia es igual a la suma de los pesos de los enlaces que conectan los dos nodos; cuando r=1 la distancia es igual a la distancia euclídea entre los dos nodos; cuando r=8 la distancia es igual al mayor de los pesos de aquellos enlaces que conectan dos nodos. Por otro lado el parámetro q indica la longitud máxima (contabilizada en número de enlaces) del camino entre dos nodos en la que no podrá violarse la 'condición de la inigualdad del triángulo'.
Una vez realizada la poda de enlaces, para la representación visual de la red, es necesario aplicar algún algoritmo de posicionamiento de los nodos. Si bien técnicas de reducción de la dimensión como el MDS (de la que hablaremos en el siguiente apartado) podrían ser útiles, tienen el problema de que al no tener en consideración la estructura de enlaces resultado de aplicación del método de Pathfinder , el posicionamiento final de los nodos provocaría cruces entre los enlaces que oscurecerían la visualización del grafo (Fowler et al. 1992).
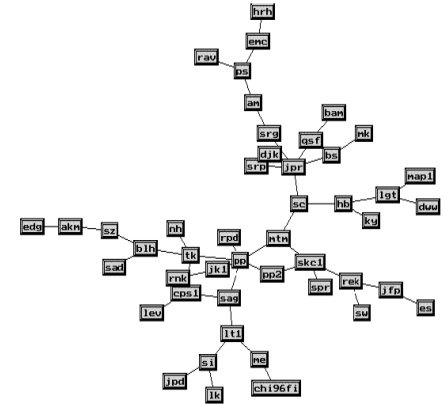
Por ello, este posicionamiento de nodos se realiza normalmente mediante algoritmos basados en 'spring models', como el desarrollado por Kamada y Kawai (1989). Estos algoritmos consideran que los nodos de la red se encuentran conectados por 'muelles virtuales', cuya fuerza es igual a la suma de los enlaces existentes entre los nodos. El algoritmo intenta reducir la tensión global del conjunto de muelles mediante un proceso iterativo de reposicionamiento de los nodos, hasta lograr la posición óptima de todos ellos.
Una forma alternativa de representar visualmente estructuras de datos multidimensionales es en forma de nubes de puntos o nubes de dispersión. Estos puntos � que visualmente no tienen por qué tener dicha forma, ya que podrían ser presentados como iconos o como rótulos de texto - estarían distribuidos en un espacio visual bidimensional o tridimensional, y distanciados unos de otros en función de las disimilaridades o distancias originales especificadas en la matriz de similaridad.
Para poder presentar estas distancias en dimensiones comprensibles por el ser humano, es necesaria la utilización de técnicas de reducción de la dimensión. Este es el caso de la técnica de estadística multivariante denominada Escalamiento Multidimensional o MDS (Multidimensional Scaling).
Este método consiste en un proceso iterativo en el que se van recolocando o re-posicionando los diferentes elementos (documentos, términos, etc.) hasta conseguir que disten entre sí lo más acercadamente a como lo hacen en la matriz original de distancias. Inevitablemente, existe una pérdida de información, mayor cuanta más diferencia exista entre el número de dimensiones del espacio multidimensional original y el número de dimensiones al que pretende ser reducido.
Esta pérdida de información o distorsión de las distancias originales entre elementos suele ser medida a través de la métrica de stress propuesta por Kruskal (1964) (originalmente el autor la denominó STRESS, acrónimo de STandardized Residual Error Sum of Squares). En la aplicación de los algoritmos de MDS, como paso previo, se suele establecer un umbral de stress aceptable, con el objetivo de reducir el tiempo de procesamiento.
Las representaciones visuales basadas en mapas se fundamentan en la idea de utilizar la metáfora de mapa geográfico para la visualización de espacios de información. Por lo general, el objetivo de la utilización de cualquier tipo de metáfora visual en el diseño de interfaces es hacer visible para el usuario la estructura y relaciones en un conjunto determinado datos. Por tanto, la idea de utilizar estas metáforas para la visualización de espacios de información complejos y abstractos parece tener bastante sentido, ya que brindan una visión diferente del conjunto que en la mayoría de los casos enriquecerá la imagen mental previa que el usuario tenga de él.
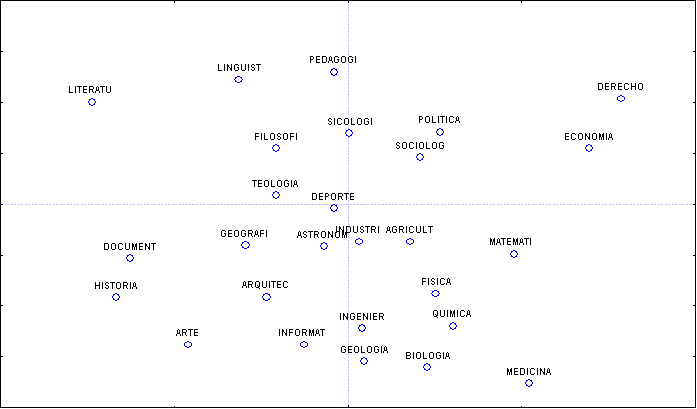
De entre todas las técnicas posibles para generar este tipo de mapas, resaltamos el modelo de mapas auto-organizativos o SOM (Self-Organizing Map) (Kohonen 1989) - aplicación de las Redes Neuronales Artificiales (RNA) para la organización y clasificación automática de información.
El funcionamiento de este modelo es sencillo, pues se basa en establecer una correspondencia entre la información de entrada y un espacio de salida de dos dimensiones. De esta manera, los datos de entrada con características comunes activarán zonas próximas del mapa. Este modelo de red se representa con sus neuronas de salida dispuestas de manera bidimensional. Cuando se ingresa un vector de datos a la red, ésta reacciona de forma tal que solo una neurona de la capa de salida resulta activada. A esta neurona se la denomina vencedora (winner-take-all unit) y determina un punto en el mapa bidimensional.

Lo que realmente esta haciendo la red es clasificar la información de entrada, ya que la neurona ganadora representa la clase a la que pertenece la entrada, además de que ante entradas similares se activará siempre la misma neurona. Por tanto, la red es válida para establecer relaciones, desconocidas previamente, entre un conjunto determinado de datos.
Como vemos, se trata de un proceso auto-organizativo, donde la clasificación u organización resultante se encuentra condicionada por la propia naturaleza de los datos introducidos.
Un ejemplo de 'Visual Interface for Information Retrieval'con forma de mapa SOM es el que se muestra en la figura 7. En este, los rótulos o etiquetas describen la temática, y el coloreado representa la densidad documental de la zona del mapa.
Los diferentes métodos descritos, clasificados en este trabajo en función del tipo de representación visual resultado de su aplicación, pueden ser considerados complementarios ya que ofrecen diferentes soluciones para un mismo problema (Herrero-Solana 2000). Aunque con funcionamiento y procedimientos diferentes, todos comparten el objetivo de la reducción de estructuras de datos multidimensionales a formas 'visualizables' en 2 y/o 3 dimensiones.
En cualquier reducción, simplificación o resumen de conjuntos complejos de datos, se produce una pérdida de información respecto a la realidad estructural de los datos originales. Es precisamente en función de aquella información estructural más fielmente preservada, que se fundamenta uno de los criterios a través del cual pueden ser caracterizados y comparados los métodos descritos.
Como afirma Kaski (1997), tras una exhaustiva comparación entre los métodos de MDS y SOM, mientras que el primero se orienta a la preservación de su estructura a través de las distancias entre elementos, los mapas auto-organizativos intentan preservar su topología o relaciones de vecindad.
Por otro lado, las técnicas de escalamiento Pathfinder generan representaciones en forma de grafos, donde lo que se preserva y enfatiza son las relaciones locales entre elementos, representadas mediante arcos o enlaces entre nodos (Chen 1998).
La información preservada mediante las técnicas de clustering es aquella representada por las relaciones de grupo entre elementos. Aunque se han demostrado muy útiles como técnicas de clasificación y visualización de información, las técnicas de clustering no son tan utilizadas como las anteriores en la producción de interfaces visuales. Esto es debido, en parte, por la imposibilidad para etiquetar o rotular automáticamente cada uno de los grupos y subgrupos creados, por lo que el usuario solo podría identificar la clase o grupo a través de la exploración de sus elementos contenidos, y la metáfora jerárquica perdería utilidad. Por estas razones, las técnicas de clustering, en el contexto de la producción de 'Visual Interfaces for Information Retrieval', son más útiles como complemento al resto (MDS, SOM y Pathfinder) que como solución per se.
| Técnica | Elementos que preserva de la estructura |
|---|---|
| MDS | Distancia entre elementos |
| Clustering | Relaciones de agrupación |
| Pathfinder | Relaciones locales más fuertes. |
| SOM | Relaciones de vecindad. |
La preservación de un determinado elemento estructural (y por tanto la pérdida de otra información), condicionará la expresividad de la interfaz resultante, es decir, el grado de fidelidad con el que los datos originales se ven representados por la estructura visual de la interfaz. Al mismo tiempo, la elección de una u otra técnica condicionará la efectividad de la interfaz, la facilidad de interpretación y comprensión de ésta por el usuario.
Existen trabajos que ponderan estas técnicas, como es el caso de la tesis doctoral de Buzydlowski (2003) donde el autor compara SOM y Pathfinder , pero el grado de expresividad de cada técnica está fuertemente influenciado por la naturaleza de los datos, por lo que no es posible afirmar que ninguna de ellas sea superior en todos los contextos.
En cambio, la efectividad y facilidad de interpretación de la metáfora visual resultante sí puede ser determinada independientemente de la naturaleza de los datos. La metáfora de grafo propia de Pathfinder resulta de mayor familiaridad para el usuario, por lo que es previsible que interfaces creadas con esta técnica resulten más usables que las creadas con MDS o SOM. Las interfaces basadas en MDS y SOM pueden resultar igual de insólitas para el usuario, aunque el orden visual de los elementos en interfaces SOM puede ser una ventaja frente al aparente caos o desorden de elementos en dispersión en interfaces MDS.
La comparación entre estos métodos se puede realizar en base a otras variables igualmente importantes, como: escalabilidad, carga computacional, posibilidad de interpretación de dimensiones, distribución visual (estática o dinámica), y escala (global o local) en la que pueden ser aplicados de forma óptima (Börner et al. 2003). Algunas de estas variables son de vital importancia, como es el caso de la carga computacional del algoritmo, lo que suele conllevar descartar algoritmos pesados como MDS cuando la generación de la interfaz se deba producir en tiempo real (Buzydlowski et al.).
Aunque las técnicas de clasificación y distribución visual descritas hasta el momento tienen el objetivo de hacer visible para el usuario el espacio documental en su conjunto, reduciendo todas sus relaciones de similaridad y estructura a un simple 'pantallazo', estas representaciones gráficas no siempre son fáciles de explorar visualmente debido a su tamaño y complejidad, provocando lo que ha venido a denominarse como 'sobrecarga visual'.
En estos casos es necesario proveer a la interfaz de mecanismos dinámicos e interactivos que faciliten su visualización por el usuario y que reduzca esta sobrecarga.
Estas técnicas podemos denominarlas de transformación visual interactiva, y su investigación es anterior a los estudios sobre VI, ya que son necesarias desde el mismo momento en que surge el problema de tener que presentar en una reducida pantalla de ordenador más información de la que puede mostrar de forma simultánea.
Gutwin y Fedak (2004) clasifican estos mecanismos en cuatro grupos diferentes: panning, zooming, múltimes vistas y focus+context. Los tres primeros grupos podrían ser considerados como técnicas no orientadas a la distorsión, mientras que el grupo de focus+context englobaría aquellas orientadas a la distorsión visual (Leung & Apperley 1994).
| Técnicas de transformación visual interactiva | ||
|---|---|---|
No orientadas a la distorsión visual -> |
Panning |
<- Vista parcial |
Zooming |
||
Múltiples vistas |
<- Vista detalle + vista global |
|
Orientadas a la distorsión visual -> |
Focus+Context |
|
Las técnicas de panning consisten en ofrecer al usuario un mecanismo para paginar o hacer 'scroll' en la interfaz, mientras que las de zooming ofrecen la opción de agrandar o ver en detalle una parte de la interfaz. Estas técnicas, que pueden ser utilizadas conjuntamente, comparten el problema de que por sí solas pueden resultar desorientadoras para el usuario, ya que sólo permiten visualizar simultáneamente una parte de la interfaz sin tener una visión global de ésta (Storey et al. 1999).
Una posible solución para este problema es el empleo de técnicas de 'múltiples vistas' o Detail+Overview , que se basan en ofrecer desde la interfaz diferentes vistas de la misma representación visual. Al mismo tiempo se ofrece una visión global de la representación para orientar al usuario, y por otro una vista para su exploración visual en detalle. Igualmente se proporcionan mecanismos interactivos para especificar el nivel de detalle (zoom), así como para seleccionar qué parte de la representación se quiere observar en detalle.
Como ejemplo de su aplicación en la producción de 'Visual Interfaces for Information Retrieval', podemos observar su uso para la visualización de representaciones complejas de categorías mediante redes Pathfinder en la figura 8.
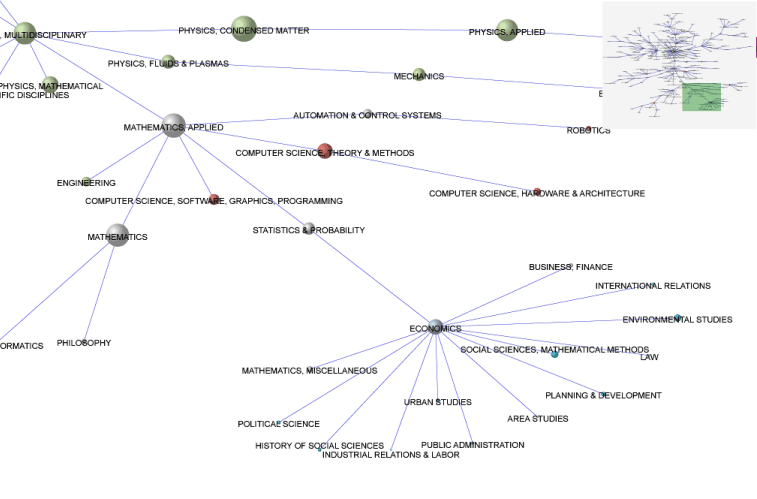
Las técnicas Focus+Context pueden ser utilizadas como alternativa a las técnicas Detail+Overview , e incluso, en algunos contextos, como complemento a éstas (Hayama et al. 2003).
La idea consiste en ofrecer al usuario, a través de una única vista, tanto una visión en detalle de la representación visual, como una visión global. Las premisas de las que parte esta técnica son las siguientes (Polanco & Zartl 2002):
De acuerdo a estas premisas, el funcionamiento de las técnicas de Focus+Context consiste en distorsionar la representación visual, haciendo más visible el foco y minimizando el contexto. Para realizar esta distorsión, las técnicas de Focus+Context pueden hacer uso de dos procedimientos:
Aunque variando en las funciones de magnificación que emplean para realizar esta distorsión visual (Leung & Apperley 1994), podemos afirmar que las técnicas Focus+Context conceptualmente tienen en común el efecto visual que persiguen, denominado genéricamente de ojo de pez (Fisheye), en el que se magnifica el foco de atención y se minimiza la zona visual contextual o periférica.
A pesar de que existen propuestas previas conceptualmente similares como la vista bifocal (Spence & Apperley 1982) posteriormente extendida por Mackinlay et al. (1991); fue Furnas (1986) quien formalizó el concepto de ojo de pez como tal, a través de su función de Grado de Interés o DOI (Degree Of Interest), que asigna a cada elemento visual un valor que representa el interés del usuario en visualizarlo.
DOI(x, y) es el grado de interés que para el usuario tiene el elemento x, cuando el elemento foco que se está visualizando es y. API (x) es el valor global de la Importancia A Priori (A Priori Importance) que tiene el elemento x, y D(x, y) la distancia existente entre el elemento x y el elemento focal y .
En su trabajo, Furnas aplica dicha función a estructuras textuales jerárquicas, asignando el valor de API en función del nivel jerárquico en el que se encuentre el nodo, y calculando el valor de la distancia en función del camino que habría que recorrer a través del árbol jerárquico para llegar de un nodo a otro. Por tanto, no ofrece ningún modelo matemático para su aplicación en otros contextos, como por ejemplo en las representaciones gráficas.
Existen multitud de aplicaciones basadas en el concepto de ojo de pez, que no sólo difieren en el contexto de aplicación, sino también en la forma y método. De hecho, como afirma Noik (1993), mientras que la propuesta original de Furnas estaba enfocada principalmente a la utilización de procedimientos de filtrado o elisión, muchas de las posteriores aplicaciones están basadas en procedimientos exclusivamente de distorsión o deformación visual.
Algunas de las áreas de aplicación del modelo de ojo de pez han sido: menús de interfaces gráficas de usuario (Bederson 2000); documentos textuales de estructura jerárquica (Hayama et al. 2003) (Hornbæk & Frøkjær 2003); y jerarquías complejas (Lamping et al. 1995).
En el contexto de las representaciones gráficas, Sarkar y Brown (1992) proponen un modelo matemático para la aplicación del efecto de ojo de pez en redes en forma de grafo, introduciendo dos posibles métodos de distorsión visual: por transformación cartesiana y polar. Para su aplicación en grafos, los autores introducen variaciones sobre la función DOI original, midiendo la distancia entre dos nodos D(x, y) a través del cálculo de la distancia euclídea entre estos dos vértices en la red.
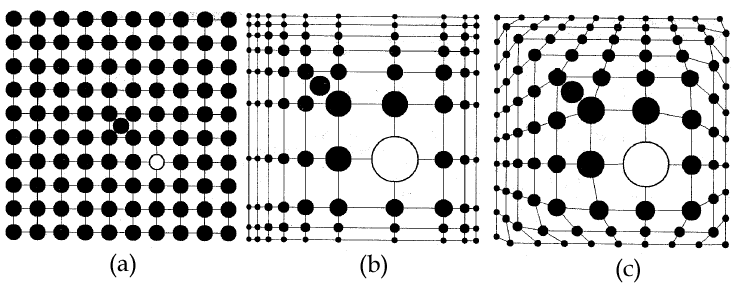
Un aspecto importante en la aplicación de estas técnicas de transformación visual en representaciones complejas, es la necesidad de preservación del mapa mental que el usuario adquiere en la visualización previa a la distorsión. Para preservar este mapa mental, una vez que se aplique el efecto de distorsión, el usuario debería poder equiparar mentalmente la representación distorsionada con aquella que visualizaba antes de la distorsión.
Para ello se deberían conservar propiedades del grafo como la dirección de las líneas, la topología, la ortogonalidad y las distancias entre elementos. Lógicamente, preservar todas estas propiedades es imposible desde el momento en que lo que se está realizando es precisamente una distorsión visual. Una posible solución la ofrecen Storey et al. (1997, 1999), quienes proponen un algoritmo para la aplicación del efecto ojo de pez en grafos, adaptable según las propiedades del grafo que quieran ser conservadas tras la distorsión, con el objetivo de preservar el mapa mental del usuario.
Más concretamente, en el área de la visualización de información la técnica de ojo de pez ha sido utilizada con éxito en varias propuestas de 'Visual Interfaces for Information Retrieval' (Fowler et al. 1992; Orimo & Koike 1999; Rennison 1994; Chen 1998; Turetken & Sharda 2003 y Yang, et al. 2003).
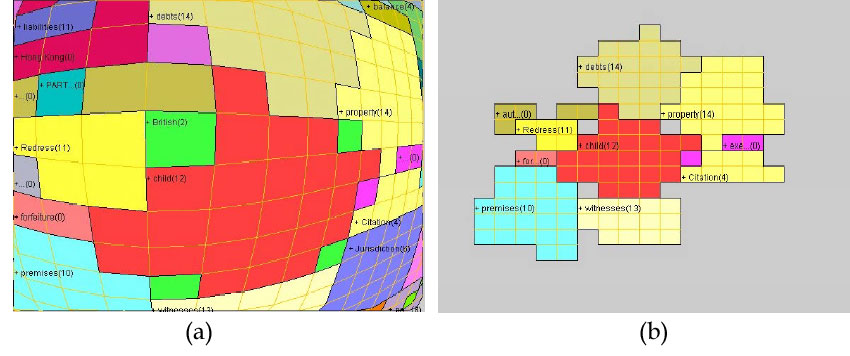
Como ya indicábamos, las técnicas de panning y zooming, aunque útiles en ciertos contextos, al no proporcionar una visión global de la representación no resultan del todo apropiadas para representaciones visuales complejas. De hecho, como se demuestra en varios trabajos (Schaffer et al. 1996) (North & Shneiderman 2000) (Gutwin & Fedak 2004), las técnicas de Overview+Detail así como Focus+Context, presentan una mayor efectividad demostrada en este tipo de interfaces visuales.
Por otro lado, la técnica Overview+Detail, aunque es ampliamente utilizada en multitud de contextos, presenta algunos problemas como es la desconexión visual entre la vista en detalle y la vista global (Parker et al. 1998) (Storey et al. 1999), que pueden ocasionar dificultades para apreciar de forma precisa la relación entre la zona visualizada en detalle y su contexto. Otro problema es que requiere por parte del usuario la integración mental de ambas vistas (Schaffer 1996; Yang, et al. 2003), lo que podría repercutir en una 'sobrecarga cognitiva'. Por estos motivos en determinados contextos la aplicación de técnicas de panning y zooming por sí solas, ofrecen incluso mejores resultados que la de Overview+Detail en cuanto a eficiencia en la consecución de tareas por el usuario (Hornbæk et al. 2002).
Aunque en base a esto podríamos concluir que las técnicas Focus+Context serían las más adecuadas para su empleo en 'Visual Interfaces for Information Retrieval' complejos, coincidimos con Storey, et al. (1999) cuando afirman que existe una preocupante carencia de estudios de análisis y evaluación que determinen la validez de estas técnicas de distorsión visual de forma empírica.
Una notable excepción es el trabajo de Yang, et al. (2003), donde sobre un 'Visual Interface for Information Retrieval'con forma de mapa de categorías y generado mediante el modelo de mapas auto-organizativos (SOM), aplican diferentes técnicas de transformación visual para comparar su rendimiento.
Tras evaluar el 'Visual Interface for Information Retrieval'a través de un test de usuarios, los autores concluyen que tanto la técnica de ojo de pez (basada en procedimientos de distorsión de información visual), como la técnica de fractales (Koike 1995) (basada en procedimientos de filtrado de información visual), incrementan la eficacia en la visualización de grandes mapas de categorías frente a la no utilización de ninguna de ellas. La técnica de filtrado según sus resultados, en este tipo de mapas, parece ofrecer cierta ventaja frente a la de distorsión; mientras que entre los métodos de distorsión aplicables en la técnica de ojo de pez, el método de transformación cartesiana es preferida por los usuarios frente al método de transformación polar.
A lo largo de este trabajo se han descrito, analizado y comparado entre sí las posibles técnicas y métodos a emplear por cada una de las etapas de la producción de un VIRI, pero aún cabe cuestionarse qué posibles combinaciones entre técnicas de diferentes etapas ofrecen resultados más adecuados.
Obviando la etapa de análisis y transformación de los datos, donde concluimos que las diferentes técnicas de minería de datos eran complementarias entre sí e idealmente se debían usar conjuntamente en forma de análisis de meta-similaridad; es necesario determinar la compatibilidad entre las técnicas de la etapa de clasificación y distribución visual y la etapa de transformación visual.
Las técnicas de transformación visual son necesarias cuando la representación gráfica producto de la etapa anterior resultaba compleja y de difícil visualización. Este hecho no sólo depende de la cantidad de datos a resumir y representar en la interfaz, sino también del algoritmo o técnica de clasificación y distribución visual empleados.
Mientras que hay algoritmos de distribución visual que aprovechan de forma óptima el espacio visual de la representación resultante, otros en cambio tienden a desaprovechar y aglomerar los elementos, repercutiendo negativamente en la facilidad de visualización. Este es el caso de la técnica de MDS, en cuyas representaciones es muy frecuente la aglomeración y solapamiento de elementos, lo que aumenta la necesidad de emplear técnicas interactivas de transformación visual que faciliten la exploración visual de la interfaz.
En redes PFNETs, en cambio, la aglomeración de elementos es menor, debido al propio funcionamiento de los algoritmos de posicionamiento spring models , por lo que el empleo de técnicas de transformación visual normalmente sólo resulta necesario cuando el número de nodos y/o arcos a representar es muy elevado.
Por último el algoritmo SOM es el que mejor aprovecha el espacio visual, ya que en su representación gráfica no existen zonas 'en blanco'. Esto significa que la aplicación de técnicas de transformación visual suele ser en la mayoría de casos innecesaria.
Además del hecho de que la técnica empleada en la etapa de distribución visual influirá en la necesidad de emplear o no técnicas de transformación, también se debe tener en cuenta que no todas las técnicas de transformación visual son igualmente adecuadas y compatibles con todas las de distribución visual.
| MDS | SOM | PFNETS | |
|---|---|---|---|
Focus+Context |
- |
√ |
- |
Detail+Overview |
x |
- |
√ |
Zoom and Panning |
√ |
√ |
√ |
Las técnicas de zoom and panning , por su simplicidad y al no tratarse de técnicas de distorsión, pueden ser utilizadas sobre representaciones generadas con cualquiera de los métodos de distribución y clasificación visual sin problemas.
Por otro lado, las de 'vistas múltiples' o Detail+Overview no son aconsejables sobre representaciones de dispersión generadas por MDS. Estas representaciones, al contrario que las redes en forma de grafos, no poseen una estructura global clara y reconocible, por lo que la vista global u Overview no ofrecerá valor orientativo durante la visualización de la interfaz por el usuario. En cambio, las representaciones en forma de grafos generadas mediante técnicas Pathfinder , sí poseen una estructura global reconocible modelada por los arcos entre nodos, resultando en este caso de valor el empleo de técnicas Detail+Overview .
La combinación de técnicas Detail+Overview y SOM no es por definición inadecuada, aunque su grado de adecuación dependerá directamente de la forma del mapa obtenida y cómo de reconocible resulta su estructura global.
Por otro lado, la naturaleza distorsionadora de las técnicas Focus+Context , si bien es la que les confiere su mayor potencial como técnicas de transformación interactiva, también es causa de problemas en su combinación con MDS y PFNETs.
La aplicación del efecto 'ojo de pez' sobre representaciones MDS ofrece problemas desde el momento que se realiza mediante procedimientos de deformación visual sobre las posiciones de los elementos. Como se ha comentado, las técnicas MDS se caracterizan porque la información estructural preservada de los datos originales es la relacionada con las distancias entre elementos, información que finalmente se perdería cada vez que se aplicase este efecto de transformación sobre las posiciones de los elementos. Es previsible que métodos como el de transformación cartesiana minimizarán este problema frente a métodos como el de transformación polar.
En redes PFNETs la transformación de las posiciones de los nodos, aunque también influye en la expresividad de la representación, no implica la misma problemática, puesto que la información preservada mediante técnicas pathfinder es la de las relaciones locales más fuertes entre nodos, información que no se pierde con la aplicación del 'ojo de pez'.
Finalmente, los mapas SOM parecen ser especialmente adecuados para este efecto visual, puesto que la información de las relaciones de vecindad de elementos no se vería modificada por la aplicación del efecto de 'ojo de pez', además de que existen trabajos (Yang, et al. 2003) en los que ya ha sido probada su efectividad.
Es lógico que dada la cantidad de posibles combinaciones de técnicas, algoritmos y tipos de análisis en la generación de interfaces visuales para la recuperación de información, no todas las combinaciones hayan sido exploradas o investigadas.
Debido a que el objetivo de este trabajo es precisamente servir a otros investigadores como herramienta para la elección de una u otra combinación de técnicas en el desarrollo de propuestas específicas de 'Visual Interfaces for Information Retrieval'; se ha puesto especial énfasis en las técnicas de transformación visual, ya que consideramos que han sido menos estudiadas y aplicadas en la producción de 'Visual Interfaces for Information Retrieval'.
Al igual que las técnicas de clasificación y distribución, las de transformación visual tienen por objetivo simplificar espacios complejos de información, en este caso de la información visual que conforma la interfaz final. Esta simplificación no sólo se encuentra motivada para posibilitar la comprensión de grandes volúmenes de información que de otra forma no podrían ser interpretados por el usuario, sino también para facilitar esta visualización e interacción entre usuario e interfaz.
En este sentido creemos necesaria la investigación sobre nuevas técnicas de transformación visual interactiva o sobre nuevos modelos de aplicación de las existentes. Como hemos visto, aquellas técnicas de distribución visual que dan como resultado representaciones más complejas de visualizar, son precisamente las menos compatibles con las descritas técnicas de transformación interactiva. E igualmente, las técnicas de transformación interactiva que más compatibilidad ofrecen con las de distribución, resultan ser las que menos ventajas ofrecen en su tarea de facilitar la exploración visual de la interfaz.
No debemos olvidar que la divulgación y aceptación de este tipo de interfaces visuales por el público general no se encuentra frenada por su utilidad o no como herramientas de recuperación de información, sino por la dificultad de aprendizaje y uso que presentan para el usuario final.
La reducción de la carga visual de la interfaz, y por tanto de la carga cognitiva del usuario en la interacción con dicha interfaz, supone actualmente el más importante reto a superar en la investigación científica sobre producción de interfaces visuales para la recuperación de información.
Introduction. In recent years the volume of electronic information has grown exponentially. This phenomenon improves data exchange and communication but introduces new troubles in relation to information access and searching.
Aim. This paper proposes an exhaustive review of the different models, methods and algorithms that can be used to develop Visual Interfaces for Information Retrieval. The methods are classified on the basis of the stage of the process in which they take part: data analysis and transformation, application of classification and visual distribution algorithms, and application of visual transformation techniques.
Methodology. Based on the analysis, we compare the different methods that can be used in each stage of the production process. We also determine which combinations of methods and algorithms are most suitable at different stages.
Results. In the first section, data analysis and transformation, we analyse content mining, structure mining and use mining. In the second section, visual classification algorithm, we shown the hierarchical, network, scattering and map representations. In the last section, visual transformation techniques, we present the distortion (Focus+Context) and non-distortion techniques.
Conclusion. The results aim to become useful tools for other researchers when choosing a methodological combination for the development of specific proposals for visual interfaces for information retrieval, as well as suggest implications to be considered on the research of new visual transformation techniques.
| Find other papers on this subject. |
|||
© the authors, 2006. Last updated: 14 March, 2006 |
|
