Vol. 12 No. 3, April 2007
| Vol. 12 No. 3, April 2007 | ||||
No conjunto das diversas áreas que envolvem a Ciência da Informação, a recuperação inteligente da informação ocupa um espaço não totalmente compreendido por setores mais voltados a aspectos relacionados com o estudo de usuários. No entanto, o uso cada vez mais corriqueiro de computadores e a onda crescente de avanços em processamento textual têm gerado, na prática, uma infinidade de arquivos digitais. Esses arquivos tanto podem representar relatórios simples quanto artigos científicos, monografias, notícias de jornal, livros, enciclopédias, dicionários, páginas Web, entre outros tipos de documentos. Esse acúmulo de documentos acabou criando a necessidade de encontrar soluções para melhorar a recuperação da informação neles contida.
A aplicação de mecanismos de recuperação inteligente da informação no universo empresarial, principalmente no que se refere aos mecanismos de busca na Internet, enfatizou a importância comercial e estratégica do acesso rápido e confiável às fontes de informação. Empresas como Google (http://www.google.com), AltaVista (http://www.altavista.com) e Yahoo! (http://www.yahoo.com) tornaram-se referência no que tange à divulgação, disponibilização, organização e recuperação de informações em um contexto de acesso público e gratuito pela comunidade mundial de internautas.
A possibilidade de varrer o conteúdo textual (letras, palavras, parágrafos) dos documentos digitais gerou diversas abordagens distintas no âmbito da recuperação da informação. Uma delas será tratada neste artigo. No caso, estudar-se-á uma das técnicas de pré-processamento do texto, etapa realizada sobre os documentos digitais antes de sua indexação. Essa técnica é a radicalização, ou stemming (em língua inglesa), ou ainda determinação do radical, dentre outras denominações, que visa a reduzir variações de uma mesma raiz vocabular com a finalidade de recuperar palavras correlatas.
Infelizmente, a radicalização é um processo que implica algoritmos diferentes de acordo com a língua em questão. Na opinião de Figuerola, Gómez Díaz e López de San Román (2000: 1): "...there are notable differences between different languages in the way of forming derivatives and inflected forms, so that the application of specific techniques can produce unequal results according to the language of the documents and queries". (Nota 1)
Porter (1980) desenvolveu um algoritmo extremamente eficiente para a língua inglesa, que tem sido utilizado extensivamente, nas palavras do seu autor: 'the Algorithm has been widely used, quoted, and adapted over the past 20 years' (Porter 2005) (Nota 2). No entanto, as características da língua inglesa são distintas, por exemplo, das da língua portuguesa. Isso obriga afirmar que a radicalização em língua portuguesa deve possuir um algoritmo que esteja de acordo com a sua morfologia.
Até o momento, diversos algoritmos de radicalização foram criados para as mais diferentes línguas. Esses algoritmos são apresentados no Quadro 1.
| Língua | Algoritmo | Autoria |
|---|---|---|
| Inglês | Porter | Porter |
| KStem | Krovetz | |
| Paice/Husk | Paice e Husk | |
| Porter 2 | Porter | |
| Dawson | Dawson | |
| Português | Porter - Português | Porter |
| Orengo | Orengo | |
| Pegastemming | Gonzalez | |
| Alemão | Porter - Alemão | Porter |
| Porter - Alemão - Variação | Porter | |
| Amárico (etíope) | Alemayehu-Willett | Alemayehu e Willett |
| Búlgaro | BulStem | Nakov |
| Dinamarquês | Porter - Dinamarquês | Porter |
| Esloveno | Popovic-Willett | Popovic e Willett |
| Espanhol | Porter - Espanhol | Porter |
| Finlandês | Porter - Finlandês | Porter |
| Francês | Porter - Francês | Porter |
| Holandês | Porter - Holandês | Porter |
| Kraaij-Pohlmann | Kraaij e Pohlmann | |
| Italiano | Porter - Italiano | Porter |
| Latim | Schinke et al. | Schinke et al. |
| Norueguês | Porter - Norueguês | Porter |
| Carlberger et al. | Carlberger et al. | |
| Russo | Porter - Russo | Porter |
| Sueco | Porter - Sueco | Porter |
| Turco | Ekmekçioglu et al. | Ekmekçioglu et al. |
Apesar de a língua portuguesa possuir mais de 220 milhões de falantes no mundo ("Temática Barsa" 2005: 46), estando entre as dez mais faladas, e possuir uma baixa representação em termos de recursos ling�ísticos em relação a outras línguas européias como o francês e o espanhol (Orengo 2004: 63), pouco se fez em termos de construir um algoritmo que radicalização que acrescentasse vantagens à versão portuguesa do algoritmo de Porter, de uso público (Orengo 2004: 48).
O objetivo deste artigo, por conseguinte, é apresentar alguns dos algoritmos de radicalização para a língua portuguesa. Na primeira parte, a radicalização será definida, para que haja clareza sobre a sua significação e abrangência; na segunda parte, apresentam-se os algoritmos disponíveis para a língua portuguesa; na última parte, tecem-se algumas considerações sobre os problemas e lacunas existentes na área.
O vocábulo radical pode ser definido como o "elemento que serve de base às palavras de uma mesma família etimológica [...], e que é tomado como ponto de partida para o estudo da estrutura dos vocábulos numa língua, como luc-, luz-, em elucidar, translúcido, luzir" ("Radical" 1999: 1697).
O Dicionário Houaiss da Língua Portuguesa apresenta o seguinte significado para radical: 'parte da estrutura de uma palavra que contém seu significado básico e recebe os sufixos flexionais, como, p.ex., livro/livros; pode ou não ter afixos derivacionais: livreiro/livreiros [É simples, se constituído de um único morfema: feliz; e complexo, se constituído por mais de um morfema: infeliz (in- + feliz), livreiro (livr- + -eir- + -o).] (Radical 2001: 2374).
A palavra radicalização não remete a nenhum desses significados ("Radicalização" 1999: 1697; "Radicalização" 2001: 2374). Assim, depreende-se que radicalização apresenta um significado novo que ainda não foi incorporado ao vernáculo da língua portuguesa.
De maneira semelhante, a palavra equivalente em língua inglesa, stemming, também carece de um significado apropriado à nova idéia que procura introduzir, como atesta a sua ausência como entrada no Oxford Advanced Learner's Dictionary (1995), no The Newbury House Dictionary of American English (1999) e no Merriam-Webster Online Dictionary (2005). Convém salientar que a palavra stem seria traduzida para o português como radical.
Dessa forma, o conceito de radical norteia a definição de radicalização.
Uma outra possibilidade de nomenclatura para radicalização poderia ser normalização morfológica, apesar de aparecer dividida originalmente em dois tipos: stemming e normalização can�nica (Gonzalez et al. 2003: 2). O termo conflação também aparece na literatura, com o sentido de fusão e combinação de variantes morfológicas, segundo Chaves (2003: 2), apoiando-se em Frakes e Baeza-Yates (Nota 3).
Além das interpretações dadas por dicionários, convém levar em consideração o que gramáticos e ling�istas dizem a respeito.
Sacconi (1991: 78) define radical desta maneira: "Radical, lexema ou semantema é o elemento portador de significado, comum a um grupo de palavras da mesma família. Assim, na família de palavras terra, terrinha, terriola, térreo, terráqueo, terreno, terreiro, terroso, existe um elemento comum: terr-, que é o radical."
Um pouco mais adiante, Sacconi (1991: 79), em contraposição à semantema, define morfema: "dá-se o nome de morfema ao elemento ling�ístico que, isolado, não possui nenhum valor, servindo apenas para relacionar semantemas na oração, para definir a categoria gramatical (gênero, número e pessoa), etc."
Câmara Júnior (1980: 94) trata semantemas e morfemas como formas mínimas, "elementos últimos de significação" (Câmara Júnior 1980: 91), assim denominados de acordo com a designação proposta por Vendryes (1958: 133): "Por semantemas deben entenderse los elementos ling�ísticos que expresan las ideas de las representaciones [...], y por morfemas, los que expresan las relaciones entre las ideas [...]. Los morfemas, por lo tanto, expresan las relaciones que el espíritu establece entre los semantemas." (Nota 4)
Em suma, "o vocábulo ...é uma combinação de formas mínimas na base de um semantema e um morfema" (Câmara Júnior 1980: 93).
Contudo, semantemas e morfemas nada mais são que, lato sensu, morfemas (Câmara Júnior 1980: 91-92). Bloomfield (1969: 161) parece ter o mesmo ponto de vista: "A linguistic form which bears no partial phonetic-semantic resemblance to any other form is a simple form or morpheme. Thus, bird, play, dance, cran-, -y, -ing are morphemes." (Nota 5)
No âmbito da recuperação da informação, a radicalização é vista com algumas variâncias.
Allan e Kumaran (2003: 1) indicam uma afinidade com o entendimento ling�ístico, quando dizem que "stemming is the process of collapsing words into their morphological root" (Nota 6).
Com pouca divergência, Xu e Croft (1998: 1) afirmam que "stemming is used in many information retrieval (IR) systems to reduce variant words to common roots" (Nota 7).
De modo semelhante, para Orengo (2004: 48), a radicalização, ou stemming, "is the process of conflating the variant forms of a word into a common representation, the stem" (Nota 8).
Baeza-Yates e Ribeiro-Neto (1999: 165) definem radicalização, ou stemming, como a remoção dos afixos (prefixos e sufixos) das palavras, a qual ocorre durante o pré-processamento do texto.
Para Russell e Norvig (2004: 817), a radicalização (os autores se valem do termo traduzido como determinação do radical) é algo tão simples quanto "reduzir 'poltronas' à forma de radical 'poltrona'", ou seja, tão simples quanto eliminar o morfema gramatical de plural. Essa eliminação resulta, para a língua inglesa, em um aumento de 2% na recuperação, apesar de que os efeitos podem ser melhores com outras línguas, como o alemão, o finlandês, o turco, o inuit e o yupik (Russell & Norvig 2004: 817).
Porter (1980) indica que a sua preocupação foi remover sufixos com base em determinados critérios, sem se preocupar diretamente com os aspectos ling�ísticos: "In any suffix stripping program for IR work, two points must be borne in mind. Firstly, the suffixes are being removed simply to improve IR performance, and not as a linguistic exercise. This means that it would not be at all obvious under what circumstances a suffix should be removed, even if we could exactly determine the suffixes of a word by automatic means." (Nota 9)
Logo, pode-se sintetizar o conceito de radicalização para a recuperação da informação da seguinte maneira: radicalização é o processo de reduzir variações de uma mesma palavra a uma representação única, objetivando aumentar o nível de recuperação de documentos. Em teoria, essa representação tem a intenção de isolar o semantema das palavras dos seus morfemas, assim como na ling�ística. Contudo, não existe obrigatoriedade nesse sentido, uma vez que as representações podem ser simplificações não preocupadas com a perfeição, mas, sim, com oferecer benefícios de recuperação sem onerar o sistema e impactar na rapidez de processamento, seja no momento da indexação, seja no momento da consulta.
Na continuação, apresentam-se os algoritmos de radicalização para a língua portuguesa e, na próxima seção, apresentam-se os problemas desses algoritmos de radicalização.
Infelizmente, poucos são os algoritmos de radicalização disponíveis para a língua portuguesa. A proposta mais conhecida para a língua portuguesa é a de Orengo (2004). Segundo Silva (2004: 8), "para a língua portuguesa, dispomos dos algoritmos de Porter e Viviane Orengo", ou seja, existe uma versão portuguesa desenvolvida pelo próprio Porter (2005), seguindo as mesmas regras daquele desenvolvido para a língua inglesa. Chaves (2003: 3), além de mencionar o algoritmo de Orengo, apresenta uma outra possibilidade chamada Pegastemming, criada por Marco Antonio Insaurriaga Gonzalez.
Russell e Norvig (2004: 817) ainda dividem o processo de radicalização em dois tipos de algoritmos: os baseados em regras, que realizam operações de redução geralmente de acordo com as terminações das palavras, e os baseados em dicionário, que realizam uma checagem prévia em uma lista para evitar que todas ou determinadas palavras com características específicas sofram uma redução irregular.
O algoritmo original de Porter (1980) está baseado em regras ou critérios: "Assuming that one is not making use of a stem dictionary, and that the purpose of the task is to improve IR performance, the suffix stripping program will usually be given an explicit list of suffixes, and, with each suffix, the criterion under which it may be removed from a word to leave a valid stem. This is the approach adopted here." (Nota 10)
O algoritmo de Porter (2005) adaptado à língua portuguesa também está baseado em
regras. Cinco são os passos realizados por ele (preliminarmente, é necessário tratar as
vogais nasalizadas ã e õ):
- remoção dos sufixos;
- remoção dos sufixos verbais, se o primeiro passo não realizou nenhuma alteração;
- remoção do sufixo i, se precedido de c;
- remoção dos sufixos residuais os, a, i, o, á, í, ó;
- remoção dos sufixos e, é, ê e tratamento da cedilha.
Ao final, devem-se voltar as vogais nasalizadas à sua forma original.
O algoritmo de Orengo (2004) está baseado em regras para a remoção de sufixos. No total, apresenta 199 delas. Contudo, as regras apresentam exceções, que são tratadas com base em um pequeno dicionário de 32 mil termos, permitindo uma redução em termos de overstemming (quando parte do radical é removida pelo algoritmo) de 5% (Orengo 2004: 49 e 51). Pode-se dizer, então, que o algoritmo é um misto das duas alternativas apresentadas por Russell e Norvig.
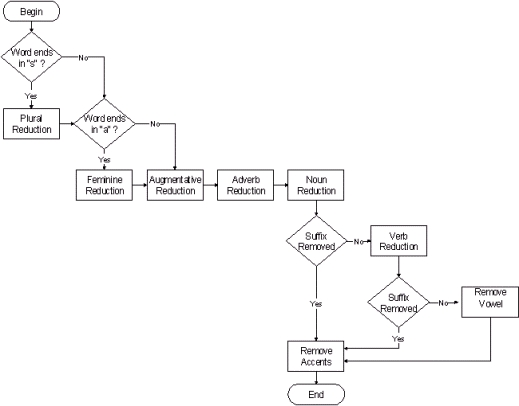
O algoritmo de Orengo (2004: 50-53) apresenta oito etapas, que são apresentadas no Quadro 2.
| Etapa | Descrição |
|---|---|
| 1. Redução do plural | Remove-se o final -s indicativo de plural de palavras que não se constituem em exceções à regra, realizando modificações, quando necessário. |
| 2. Redução do feminino | Remove-se o final -a de palavras femininas com base nos sufixos mais comuns. |
| 3. Redução adverbial | Remove-se o final -mente de palavras que não se constituem em exceção. |
| 4. Redução do aumentativo/diminutivo | Removem-se os indicadores de aumentativo e diminutivo mais comuns. |
| 5. Redução nominal | Removem-se 61 sufixos possíveis para substantivos e adjetivos. |
| 6. Redução verbal | Reduzem-se as formas verbais aos seus radicais. |
| 7. Remoção de vogais | Removem-se as vogais a, e e o das palavras que não foram tratadas pelos dois passos anteriores. |
| 8. Remoção de acentos | Removem-se os sinais diacríticos das palavras. |
Essas etapas ocorrem em uma seq�ência estabelecida previamente.
Note-se que algumas etapas são executadas apenas se determinada característica é encontrada. Isso ocorre no caso na redução do plural e na redução do feminino. Em outras duas situações, determinados procedimentos deixam de ser executados se uma etapa anterior foi realizada. É o caso da redução verbal, que só ocorre se a redução nominal não ocorreu. É, também, o caso da remoção de vogais, que ocorre somente quando a redução nominal e a redução verbal não foram feitas.
A Figura 1 apresenta o fluxograma do algoritmo de Orengo.
Chaves (2003: 3) apresenta o algoritmo Pegastemming de autoria de Gonzalez, mas não fornece muitas informações pertinentes ao seu funcionamento.
Esse algoritmo não realiza nenhum tratamento para artigos, conjunções e preposições (Chaves 2003: 4). Tal comportamento pode ser facilmente comprovado por uma visita ao sítio onde o programa de radicalização reside (http://www.inf.pucrs.br/~gonzalez/ri/pesqdiss/analise.htm) e pela visualização dos resultados obtidos a partir de documentos previamente disponibilizados.
Em geral, esse algoritmo se preocupou em implementar a remoção de sufixos comuns.
A literatura não apresenta nenhuma outra menção ao algoritmo de Gonzalez, não existindo nenhuma descrição pública disponível do seu funcionamento interno.
Russell e Norvig (2004: 817) já mencionam a possibilidade de que um algoritmo de radicalização possa prejudicar, em vez de melhorar, a recuperação das informação.
Orengo (2004: 49) simplifica os problemas existentes com a radicalização propondo duas categorias:
a) os problemas de overstemming, ou seja, quando se remove parte do radical, o que resulta na associação de palavras não relacionadas;
b) os problemas de understemming, ou seja, quando um sufixo não é removido, o que remete a uma situação em que não houve a radicalização.
De maneira específica, a língua portuguesa apresenta diversas razões para complicar o
processo de radicalização. Orengo (2004: 53-55), principalmente no que se
refere à morfologia, cita:
a) o número de exceções, dado o aparecimento comum de sufixos como terminações de palavras (o algoritmo de Porter não se preocupa com esse aspecto);
b) o número de homógrafos, que podem pertencer a diferentes classes gramaticais, interferindo na categorização dos sufixos;
c) a irregularidade na conjugação dos verbos;
d) mudanças no radical morfológico, como no caso de emissão e emitir;
e) o uso de nomes próprios, que não deveriam ser radicalizados.
O algoritmo de Orengo apresenta uma sensível melhora em relação à versão aportuguesada do algoritmo de Porter (Orengo 2004: 56).
O algoritmo de Porter reduz o tamanho do vocabulário em 44%, enquanto o algoritmo de Orengo reduz o tamanho em até 51%. Além disso, o algoritmo de Orengo gera menos erros de understemming e de overstemming (Orengo 2004: 60).
Chaves (2003: 5), em análise comparativa dos algoritmos de Gonzalez e Orengo, aferiu que o algoritmo de Orengo se comporta com melhor eficácia, gerando menos erros de overstemming e understemming no geral.
Assim, pode-se afirmar que, atualmente, o algoritmo proposto por Orengo é o mais adequado para o uso em língua portuguesa.
Apesar do funcionamento apropriado do algoritmo de Orengo e do avanço que ele representa, diversas considerações devem ser feitas.
A primeira delas envolve a própria lista de exceções. A partir do momento em que determinados termos são selecionados conscientemente por um especialista no funcionamento do algoritmo e se lhes imputa o caráter de serem exceções, parece evidente que se cria um vocabulário de pequenas proporções, cuja aparência esconde uma anterioridade objetiva, proposital. Assim, apesar de serem invocadas em situações específicas conforme o sufixo sendo removido, as exceções nada mais são do que o esforço de evitar que determinadas palavras previamente conhecidas conduzam a um problema de overstemming ou understemming. Da mesma forma, os problemas do algoritmo ficam mascarados pelos desvios sancionados pelas exceções. Por fim, a lista de exceções cita, muitas vezes, palavras pouco comuns (Orengo 2004: 136-142), preciosismo esse que pode influenciar a performance do sistema negativamente.
A segunda consideração trata de se encarar o radical morfológico, ou seja, o semantema, como o produto que deva ser gerado pelo algoritmo de radicalização. Essa idéia aparece implícita no trabalho de Orengo (2004), contudo Porter (1980) parece não ver essa questão pelo mesmo prisma. Por isso, parece ser mais interessante para um algoritmo de radicalização que a forma verbal da primeira da pessoa do singular do presente do indicativo mato seja reduzida a mat-, enquanto o substantivo mato permaneça mato. Dessa, evitar-se-ia que matem, matarás, mataria se confundissem com mato, matos na recuperação dos documentos. Nesse sentido, a normalização ling�ística parece ser uma boa hipótese a ser estudada (Arampatzis et al. 2000: 20). Todavia, cumpre salientar que os algoritmos de radicalização podem ser mais eficientes se não se preocuparem em produzirem única e exclusivamente semantemas.
A terceira consideração envolve o que se espera em nível de correção ortográfica. É de se notar que os algoritmos de radicalização partem do princípio de que o texto que processam se encontra de acordo com as regras de ortografia da língua. O algoritmo de Orengo, em vários momentos (Orengo 2004: 136-142), requer, inclusive, que a acentuação tenha sido corretamente aplicada, assim como o de Porter (2005). Partindo-se da premissa de que os textos processados pelo algoritmo de radicalização são provenientes de fontes que priorizam a correção ortográfica, chega-se a um segundo problema, que é a especificação da consulta pelo usuário do sistema de recuperação da informação, que pode ou não ter respeito às convenções ling�ísticas. Obviamente, se se consideram acentos como relevantes no processamento do texto, no momento em que o usuário erroneamente informar lençois ao invés de lençóis, o sistema de recuperação executará o mesmo algoritmo utilizado com o texto sobre a palavra-chave e retornará lençois, quando, na verdade, deveria trazer lençol (Nota 12). Isso se torna uma característica pouco adequada em situações onde não existe controle sobre a entrada de dados feita pelo usuário.
O quarto ponto envolve a incapacidade de um algoritmo de radicalização tratar todos os casos e situações possíveis. Assim, por mais que o algoritmo de Orengo (2004: 137) tenha buscado prever problemas por meio do tamanho mínimo do radical e de exceções, advérbios como somente e vãmente continuam sendo radicalizados de forma incorreta.
Em muitos casos, parece evidente que existe a necessidade de um reconhecimento morfológico-semântico das palavras, ou seja, seria satisfatório saber qual é a classe gramatical das palavras durante a aplicação do algoritmo de radicalização. Com esse tipo de informação, determinados passos de um algoritmo poderiam ser desprezados em função das características intrínsecas das palavras. Para a língua portuguesa, parece lógico que um advérbio não deva ser testado em relação a sufixos de plural; da mesma forma, sufixos verbais não deveriam ser testados com substantivos. Certamente, tal informação é difícil de depreender, uma vez que toma em consideração aspectos diversos, como termos adjacentes, pontuação e o próprio contexto. Em parte, essa é a proposta de Gonzalez et al. (2003: 8), quando realiza o etiquetamento do texto de entrada com as classes morfológicas dos itens lexicais.
Outro ponto importante na avaliação da eficácia de um algoritmo de radicalização se refere à capacidade de tratar a multiplicidade de significados. Palavras como casa (substantivo no singular) e casa (verbo na 3a. pessoa do singular do indicativo presente) apresentam significados completamente distintos, mas ambas gerariam, caso a redução fosse adotada, o mesmo radical cas-. Nessa situação, se o algoritmo não objetivasse a redução das palavras em número de letras mas focasse exclusivamente o tratamento das representações únicas, poder-se-ia ter o radical do substantivo casa como cas- e o radical do verbo casa como casar.
A última consideração trata de textos que se valem com freq�ência de termos estrangeiros, ou que são compostos por porções em mais de uma língua. Como os algoritmos de radicalização devem respeitar a morfologia de uma língua em específico, quando há termos de diferentes origens que não podem ser isolados ou corretamente identificados, o sistema de recuperação da informação tende a criar aberrações devido ao desconhecimento sobre a inserção de elementos de outro idioma no texto, até então supostamente escrito em uma única língua.
Todas as considerações acima resumem a problemática imposta por algoritmos de radicalização em língua portuguesa.
A recuperação da informação, em razão do aumento no número de documentos digitais e da necessidade inerente de pesquisar no seu conteúdo, tem-se mostrado cada vez mais importante na área da Ciência da Informação.
Uma das abordagens existentes no contexto da recuperação da informação é a chamada radicalização. A radicalização nada mais é do que a redução de variações de uma palavra em uma única representação. Apesar de existir a tendência de se associar essas representações ao semantema das palavras, não existe obrigatoriedade de correlação nesse sentido.
O algoritmo mais lembrado para a língua inglesa é o de Porter (1980), que teve adaptações para outros idiomas. Contudo, a remoção de sufixos depende da morfologia da língua a que se refere, obrigando, sempre, a existência de um algoritmo adaptado às especificidades. Para a língua portuguesa, o algoritmo mais moderno e mais completo é o proposto por Orengo (2004).
Em geral, os algoritmos de radicalização apresentam alguns problemas e lacunas: a existência de uma lista de exceções mascara as falhas nas regras dos algoritmos; a melhor forma de representar um radical nem sempre é o seu semantema; a premissa de que o texto deve estar ortograficamente correto aumenta o risco de radicalizações incorretas, principalmente no momento da recuperação; a incapacidade de tratar todas as exceções por meio de regras; a necessidade deduzida de um reconhecimento semântico anterior à radicalização; a multiplicidade de significados das palavras, que geram radicais com sentidos distintos; a existência de termos estrangeiros nos textos.
Em suma, a discussão sobre a radicalização para a língua portuguesa se abre para quatro frentes: a primeira delas leva a crer que a complexidade da língua portuguesa inviabiliza uma radicalização satisfatória dos termos; a segunda incrementa a lista de exceções à medida que elas vão surgindo na visão do modelador do sistema de recuperação; a terceira utiliza uma estrutura de dicionário que visa a criar uma lista de variações com seus respectivos radicais; a quarta se vale do reconhecimento morfológico das palavras. Dessas quatro alternativas não estão excluídas as abordagens mistas. De qualquer maneira, a perfeição não é obtida por esta ou aquela forma, atualmente, mas tão-somente pela seleção humana baseada no contexto fornecido pelo texto.
Por fim, os algoritmos de radicalização em língua portuguesa, atualmente, não se prestam à perfeição, constituindo-se num vasto campo de pesquisa sobre recuperação inteligente da informação na área da Ciência da Informação.
1. Do inglês: "...há notáveis diferenças entre línguas diferentes na maneira de gerar formas derivadas e flexionadas, tal que a aplicação de técnicas específicas pode produzir resultados díspares de acordo com a língua dos documentos e das consultas." (Figuerola, Gómez Díaz & López de San Román 2000: 1)
2. Do inglês: "o Algoritmo tem sido usado, citado e adaptado extensivamente ao longo dos últimos 20 anos" (Porter 2005).
3. Frakes, W.B., & Baeza-Yates, R. (1992). Information retrieval: data structures algorithms. Upper Saddle River, NJ: Prentice Hall.
4. Do espanhol: "Por semantemas devem ser entendidos os elementos ling�ísticos que expressam as idéas das representações [...], e por morfemas, os que expressam as relações entre as idéias [...]. Os morfemas, portanto, expressam as relações que o espírito estabelece entre os semantemas." (Vendryes 1958: 133)
5. Do inglês (os exemplos não foram traduzidos porque são características morfológicas da língua inglesa): "Uma forma ling�ística que não fornece uma semelhança fonético-ling�ística parcial com qualquer outra forma é uma forma simples ou morfema. Assim, bird, play, dance, cran-, -y, -ing são morfemas." (Bloomfield 1969: 161)
6. Do inglês: "radicalização é o processo de reduzir as palavras ao seu radical morfológico" (Allan & Kumaran 2003: 1).
7. Do inglês: "a radicalização é usada em muitos sistemas de recuperação da informação (RI) para reduzir palavras variantes a radicais comuns" (Xu & Croft 1998: 1).
8. Do inglês: "é o processo de mesclar as formas variantes de uma palavra em uma representação comum, o radical" (Orengo 2004: 48).
9. Do inglês: "Em qualquer programa de remoção de sufixos para o trabalho da recuperação da informação, dois pontos devem ser tidos em mente. Primeiramente, os sufixos estão sendo removidos simplesmente para melhorar a performance da recuperação da informação, e não como um exercício ling�ístico. Isso significa que não é de todo óbvio saber sob que circunstâncias um sufixo deve ser removido, mesmo se nós pudermos determinar de maneira exata os sufixos de uma palavra por meios automáticos." (Porter 1980)
10. Do inglês: "Tendo-se a premissa de que não se está fazendo uso de um dicionário de radicais, e que o propósito da tarefa é melhorar a performance da recuperação da informação, será dada ao programa de remoção de sufixos uma lista explícita de sufixos, e, junto a cada sufixo, o critério que diz como ele pode ser removido da palavra para gerar um radical válido. Essa é a abordagem adotada aqui." (Porter 1980)
11. Do inglês, da esquerda para a direita, de cima para baixo, não seguindo obrigatoriamente o fluxo: "Início", "A palavra termina em 's'?", "Não", "Sim", "Redução do plural", "A palavra termina em 'a'?", "Não", "Sim", "Redução do feminino", "Redução do aumentativo", "Redução adverbial", "Redução nominal", "Sufixo removido", "Não", "Redução verbal", "Sim", "Sufixo removido", "Não", "Remove vogal", "Remove acentos", "Sim", "Fim".
12. Exemplo dado com base no algoritmo de Orengo (2004).
| Find other papers on this subject | ||
© the authors, 2007. Last updated: 1 April, 2007 |
|